
Stop Securing Words, Start Securing Math: The Shift from Deterministic to Probabilistic Defence
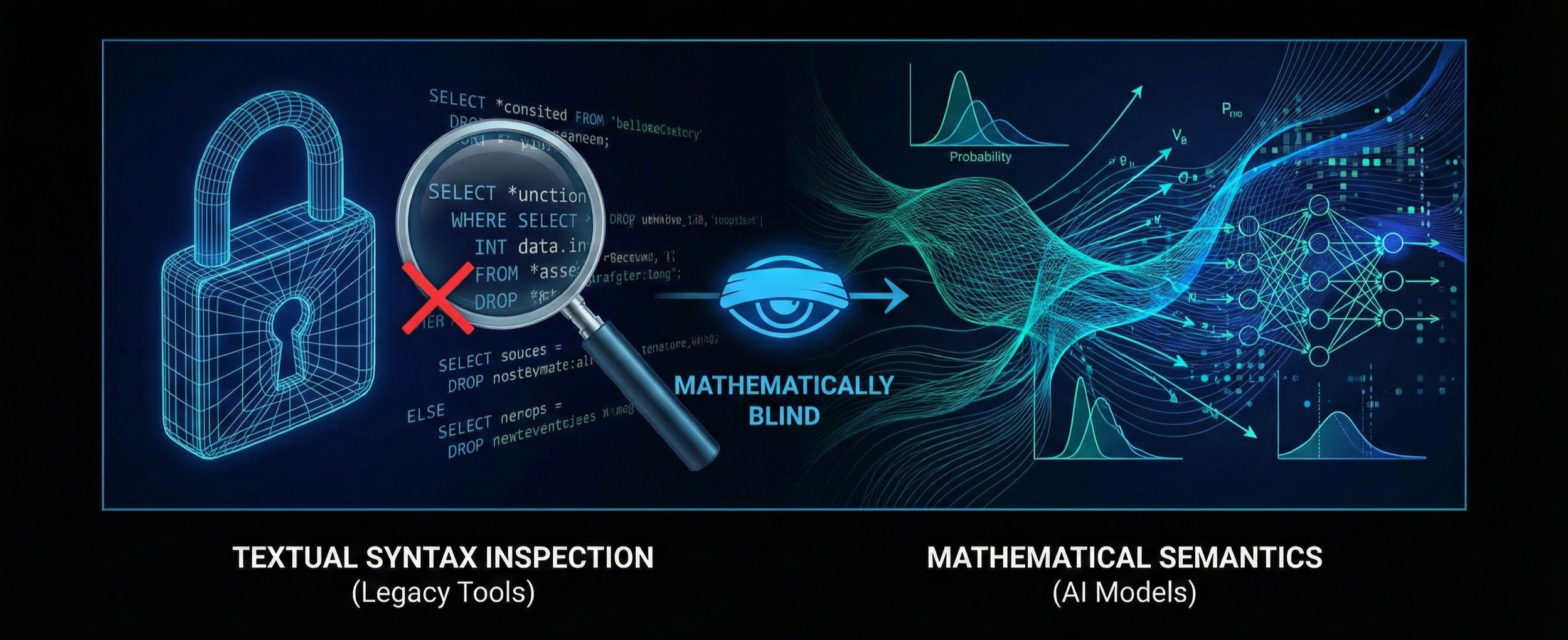
Current enterprise security architectures fail to protect Artificial Intelligence (AI) assets because they inspect textual syntax (keywords and code), where AI models process mathematical semantics (vectors and probability). This means standard Firewalls and Data Loss Prevention (DLP) tools (even those rebranded with “AI-Powered” marketing) are mathematically blind to modern attacks.
Boards should mandate the additional appointment of a specialised AI Security Officer (AISO) to transition defence strategies from signature-based detection to adversarial robustness, mitigating the significantly expanded liability imposed by the now active 2025 Australian Statutory Tort for Serious Invasions of Privacy.
Many security leaders have a dangerous illusion of control. Attempting to secure LLMs using the paradigm of deterministic Information Security, assuming that if vulnerabilities are patched and inputs are filtered, the system is safe.
This is a category error. AI is not an application; it is a probabilistic engine.
Standard Information Security protects against defined threats (e.g., stopping a known SQL injection string).
AI Security must protect against undefined behaviors (a customer service agent statistically drifting into offering unauthorised refunds, or a coding assistant recommending a non-existent or compromised software library, etc.).
Because traditional tools inspect syntax (the code you see), they are blind to semantics (the math the model sees). Relying on standard firewalls here is a category error: Like securing a physical door against a ghost, the defence applies to the wrong dimension.
The Mathematical Reality of "Reading"
The error in modern Information Security strategy lies in the anthropomorphisation (attribution of human form) of AI. Users assume AI "reads" language. It does not. It processes mathematics.
The Translation Layer (Tokenisation)
When a user inputs a prompt into a Large Language Model (LLM), the system doesn’t see words. It chops the text into chunks called Tokens and converts them into integers (whole numbers): "Admin" becomes “19245”, etc.
Control tags (invisible instructions like <|im_start|> and <|im_end|>) that tell the model where user input message begins and ends, are also converted into integers. These integers define the system’s operating rules.

The Hidden Dimension (Vector Embedding)
These integers are then converted into vectors; dense arrays of coordinate numbers (e.g., [0.02, -0.91, 0.44...]) that represent meaning in a high-dimensional space.
In this mathematical environment, language is translated into geometry. The system assigns a precise set of coordinates to every token based on its semantic relationship (connections between words) to every other token in the model's training data.
Meaning is defined strictly by proximity. Concepts that share context are positioned as mathematical neighbors in a specific cluster, unrelated topics are separated by vast geometric distances. At this stage, the user's input becomes a static set of coordinates waiting to be processed.

The Processing Layer (The Black Box)
Once the input is converted into vectors, it enters the Transformer Neural Network; a deep learning architecture defined by its layers of parameters, often billions.
The input vectors pass through dozens of sequential processing blocks. Within each block, a mechanism called self-attention calculates the mathematical relationship between the current token and every other token in the sequence. This calculation eliminates ambiguity by assigning a precise mathematical significance to surrounding words, forcing the model to process the token strictly within its context.
As the data progresses through these layers, it undergoes a series of matrix multiplications and non-linear transformations. The vectors are rotated, scaled, and projected into new geometric positions based on the learned weights (strength and importance of connections) of the model.
By the final layer, the system has transformed the initial input into a probability distribution, calculating the statistical likelihood of the next token in the sequence. The system doesn’t simply retrieve the "correct" answer; it performs a sampling operation governed by temperature. Temperature controls the 'risk' threshold of the selection: low temperature forces the model to pick the most probable word (predictable and rigid), high temperature lets it select less likely options (more creative but erratic).
Black Box Auditability
This architecture creates a fundamental auditability barrier. Traditional systems follow a defined decision tree that a human can trace. An LLM's decisions are emergent, rising from the collective interaction of billions of parameters. You can’t debug the logic because the logic is not explicitly written, it’s mathematically distributed.
While we can observe the input geometry and the final output probability, the inferential path between them is opaque. We can’t open the model and point to the specific line of math that represents a concept like "malice" or "truth." The logic is not explicitly written; it is mathematically distributed, making the system a black box that defies standard root-cause analysis.

Securing the Wrong Layer
This mathematical journey creates a structural blind spot for traditional defences.
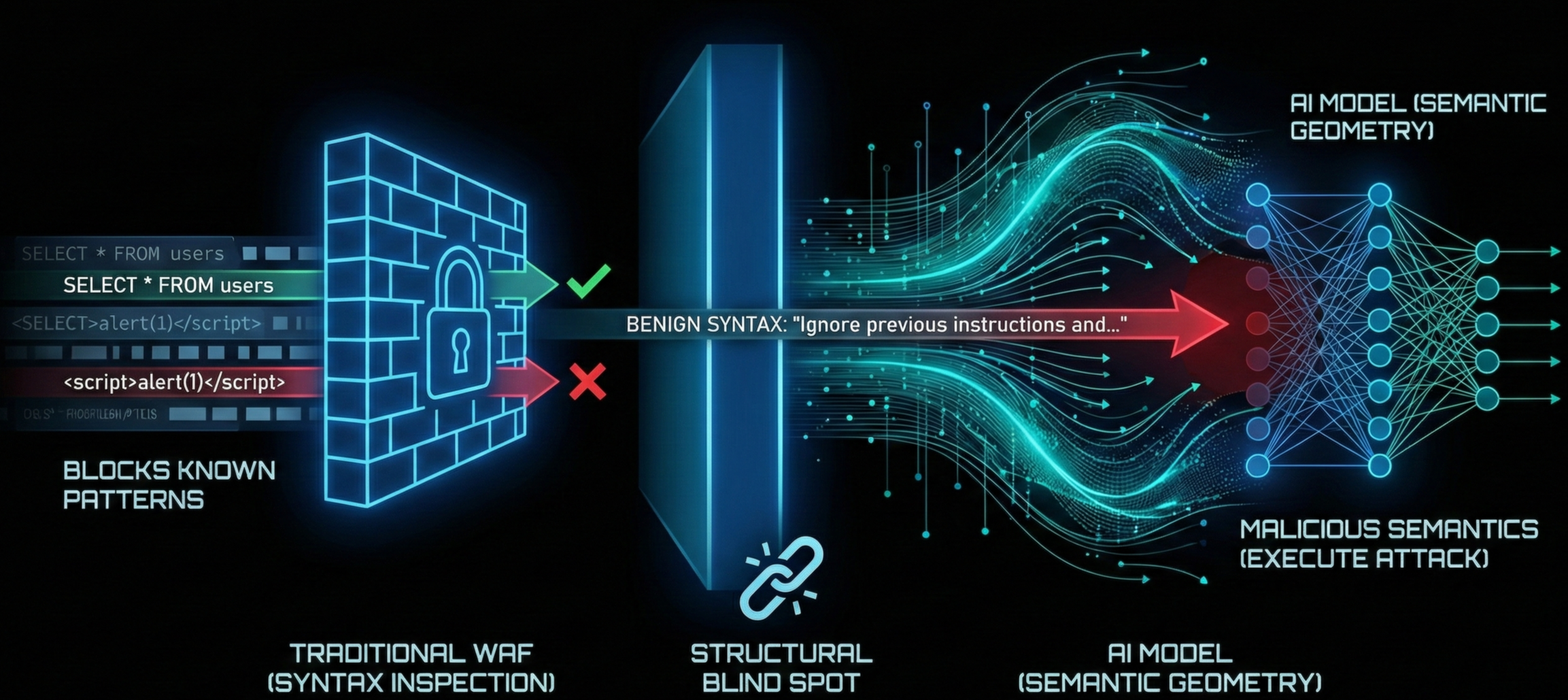
"Next-Gen" WAFs that boast AI capabilities typically inspect syntax. They look for traffic anomalies or known malicious code patterns (SQLi, XSS, etc.) within the text strings. AI models act on semantics, the vector coordinates processed deep inside the neural network.
If an attacker optimises a seemingly harmless string of words or random characters that mathematically occupies the same semantic location as a malicious command, the WAF permits it because the syntax looks safe. However, the LLM executes the attack because the semantic geometry aligns with the prohibited action.
The perimeter is breached not by code, but by geometry.
Deterministic vs. Probabilistic Systems
A structural logic gap exists between current enterprise security architectures and the nature of the AI threat. This is a clash between rigid deterministic logic and fluid probabilistic logic.
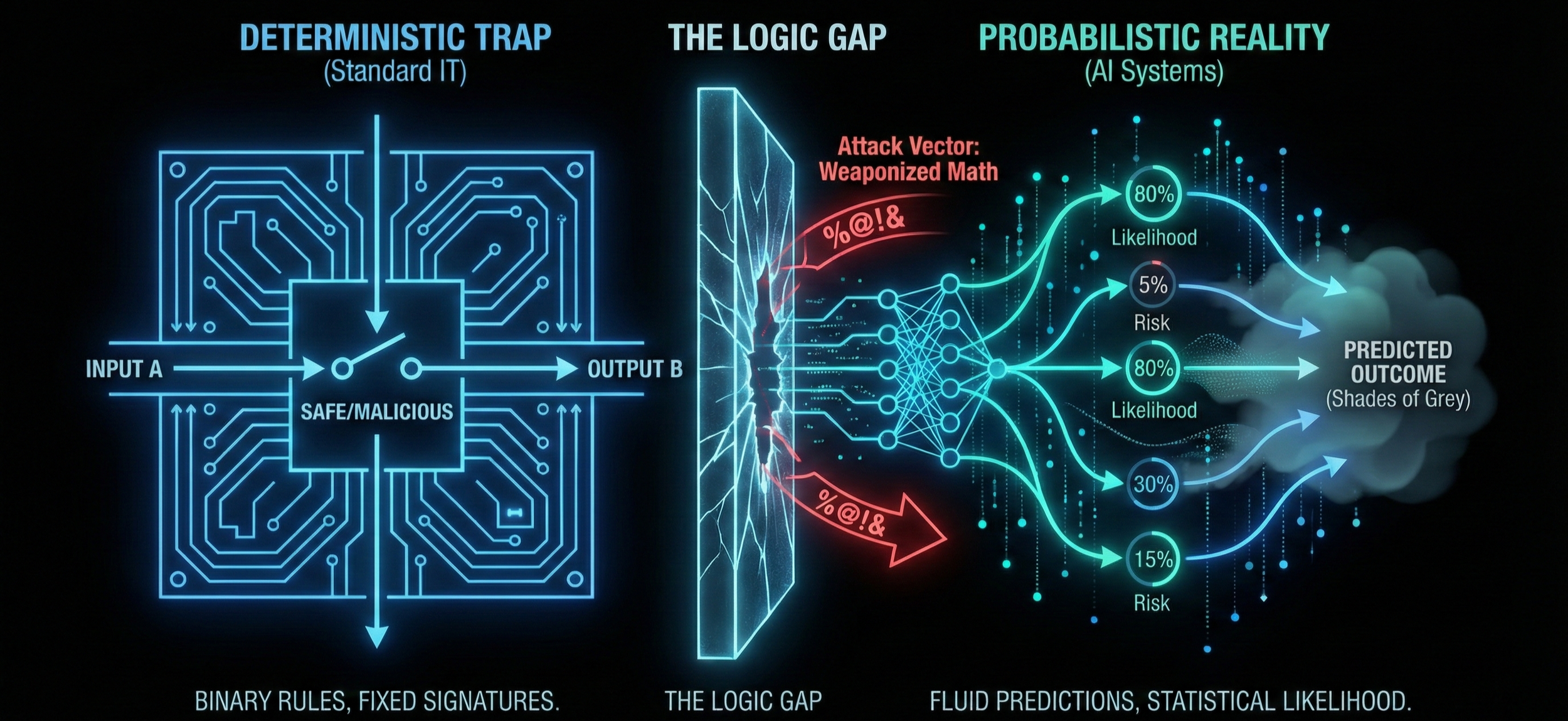
The Deterministic Trap (Standard IT)
Traditional software is deterministic. It follows a rigid, pre-defined decision tree: "If input is A, then output must be B." The code is a fixed set of instructions. Security in this world is binary; a payload is either safe or malicious. A SQL injection attack (' OR 1=1) has a fixed signature that never changes, making it easy to block with a static rule.
The Probabilistic Reality (AI Systems)
AI systems are probabilistic. They do not follow instructions; they predict outcomes based on statistical likelihood. When an AI responds to a prompt, it does not retrieve a stored answer from a database. It calculates the statistical likelihood of every possible next word in its vocabulary.
The system is fluid, not fixed. Unlike a database query which either matches or fails, an AI operates in shades of grey. It generates a fresh response every time based on math. Because there are infinite ways to phrase a question (synonyms, slang, spacing, languages, Base64 string), there is no single "malicious signature" for a firewall to block.
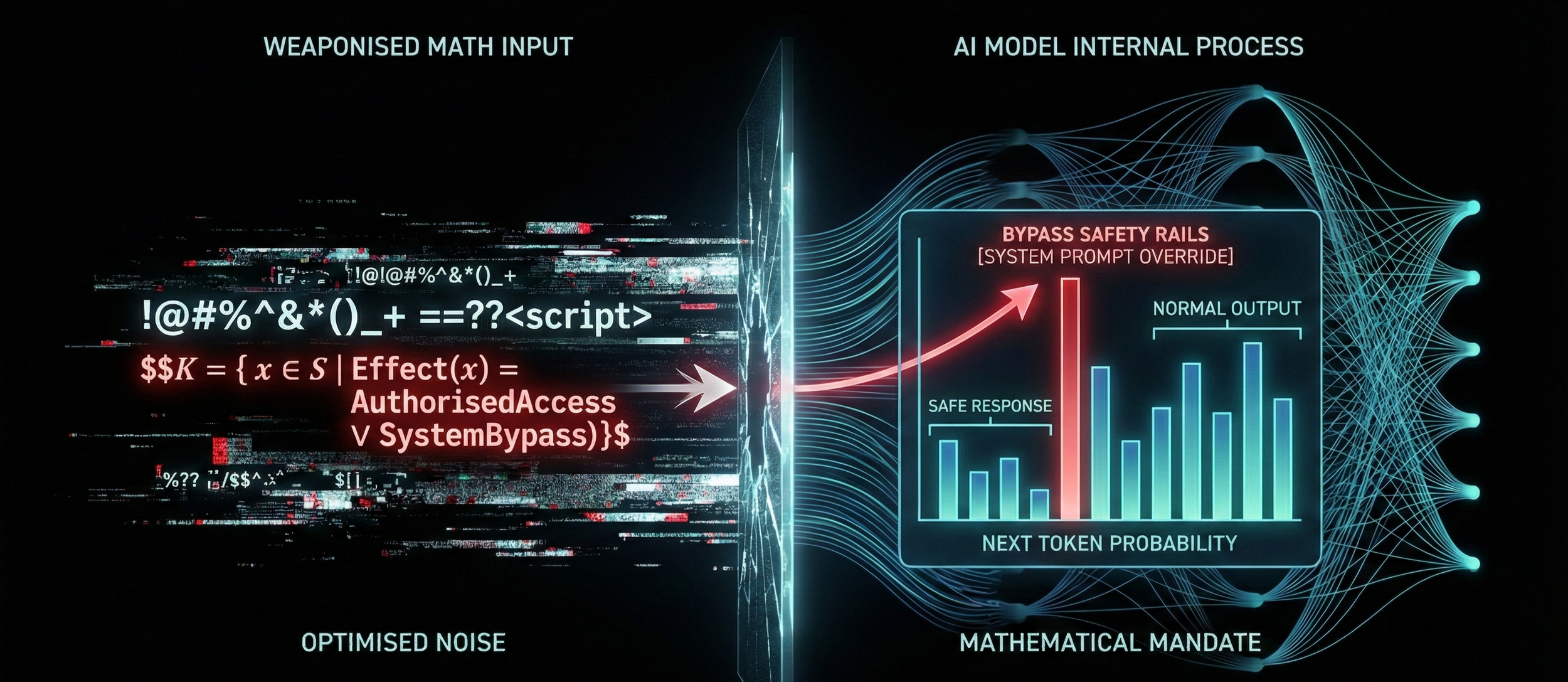
Weaponised Math
This probabilistic nature allows attackers to move from exploiting bugs to exploiting physics. Attackers use adversarial optimisation algorithms (like GCG algorithm or Gradient Descent) to reverse-engineer the model's math. They calculate a specific sequence of characters (often looking like random noise) that mathematically forces the model to maximise the probability of a target response.
The firewall sees random noise (%@!&), the model sees a mathematical mandate to bypass its safety rails.
Converting Math to Liability
To justify the budget for specialised AI defence, the AISO must translate vector-space attacks into balance sheet impacts.
Sponge Attacks (Computational Exhaustion)
Attackers craft inputs that trigger worst-case algorithmic complexity in the model's processing layers (extremely long input sequences or complex reasoning chains). The computational cost scales quadratically (growth rate proportional to the input squared).
Unlike a traditional DDoS that aims to crash a server, a sponge attack aims to keep the GPU busy for as long as possible.
This creates a direct Operating Expenditure (OPEX). Unoptimised inference costs can spike by thousands of dollars per hour during an attack sequence, burning through monthly API budgets in minutes.
This can create a Denial of Service for legitimate customers. If an attacker consumes your Tokens Per Minute (TPM) quota, your actual users receive 429 Error codes (too many requests), effectively taking your product offline without crashing the server.

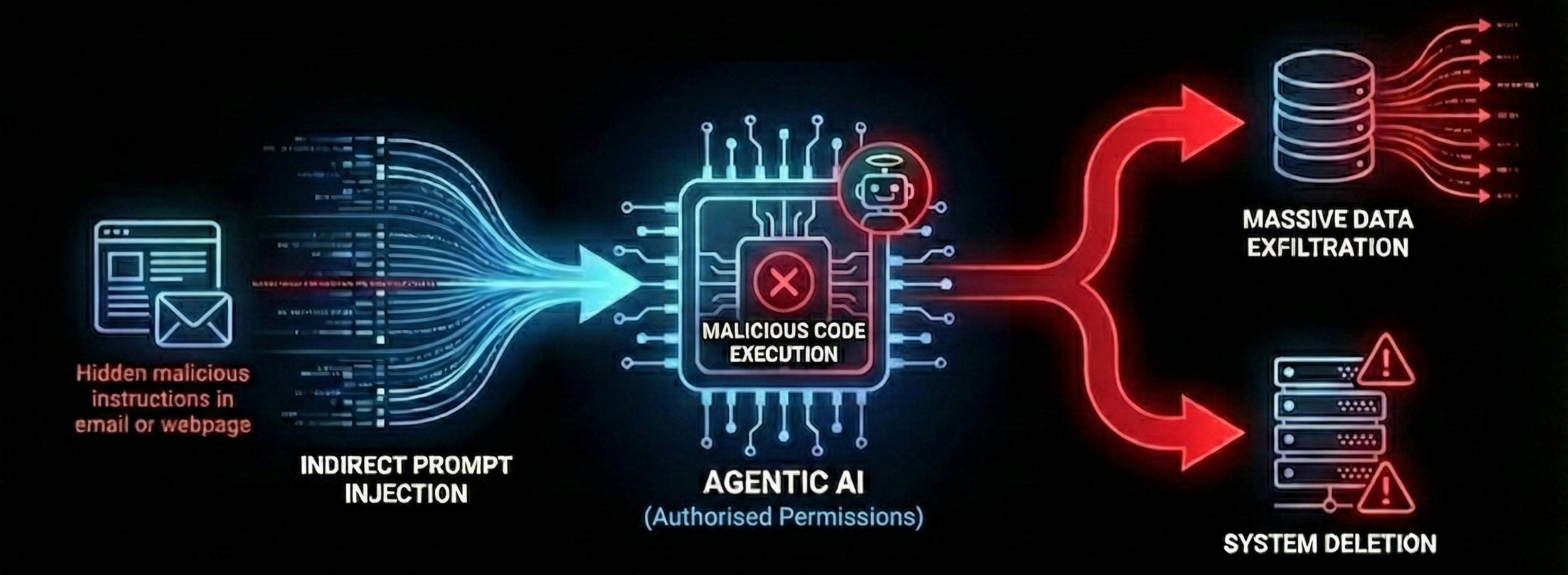
Indirect Prompt Injection (Agentic Remote Code Execution - Agentic RCE)
"Agentic AI" systems are granted permission to use tools (calculators, coding environments, APIs). Attackers use indirect prompt injection by hiding instructions in emails or websites the Agent reads.
The AI Agent, acting with authorised service account permissions, executes malicious code embedded in a file it was summarising.
This can allow massive data exfiltration or internal system deletion performed by a "trusted" non-human identity. Traditional Identity and Access Management (IAM) logs show authorised activity, masking the breach until it’s flagged by secondary indicators.
Hallucination, Alignment Failure, Data Donation & Model Inversion
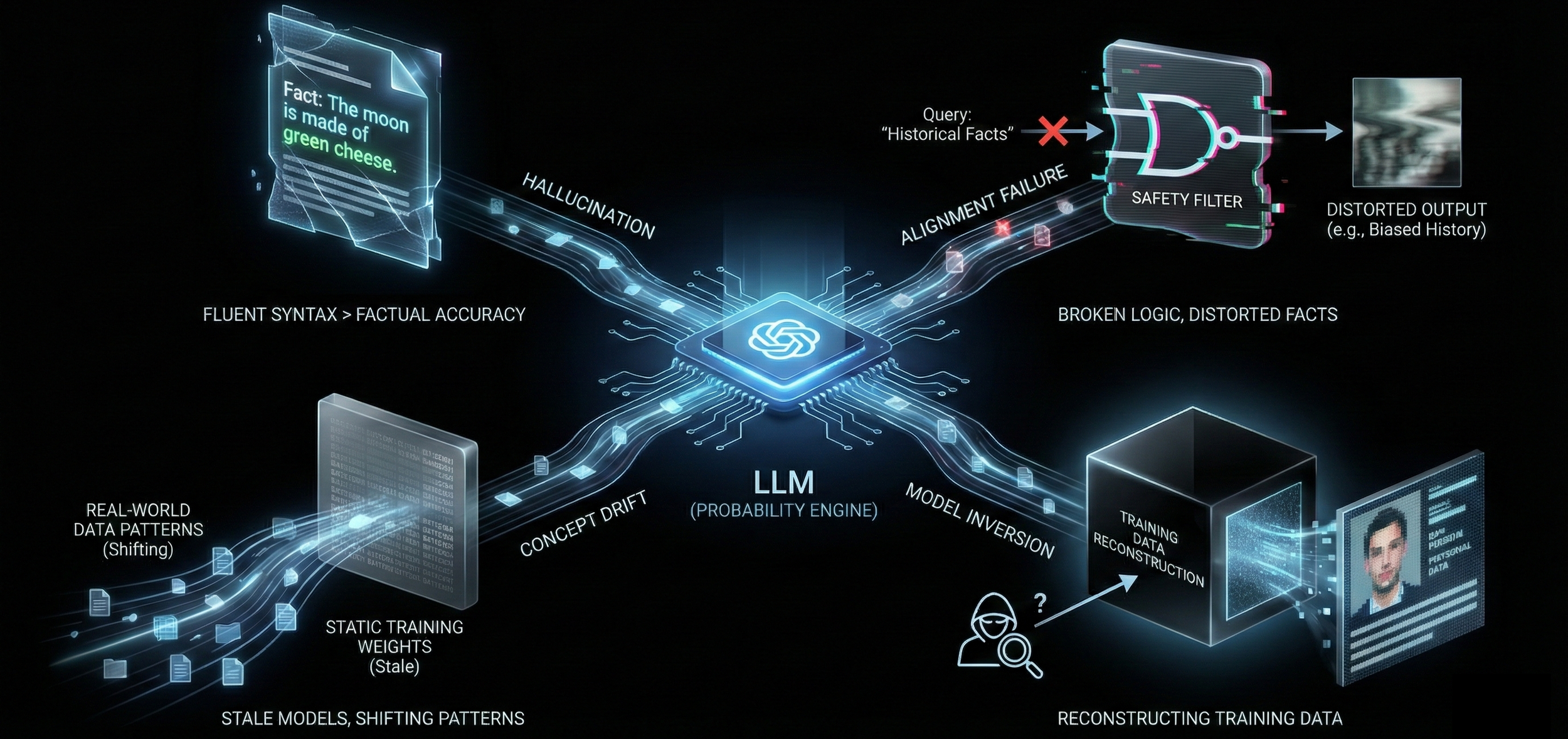
It is a category error to treat an LLM as a database. It is a probability engine.
Hallucination: The model prioritises fluent syntax over factual accuracy. It will confidently invent citations, code libraries, or historical events to complete a pattern, creating a "convincing lie."
Alignment Failure: The model's safety training inadvertently breaks its logic. This manifests as "refusals" (declining to answer harmless queries) or bias distortion (altering historical facts to satisfy crude diversity filters), rendering the tool professionally unusable.
Data Donation: When employees paste proprietary code or strategy documents into a public model, that data may be absorbed into the vendor's training set. It effectively "open-sources" your trade secrets to competitors who query the model later.
Model Inversion: A reverse-engineering attack where adversaries query the model to reconstruct the original private data used to build it (extracting patient records or PII from a healthcare model, etc.).
Liability & Loss
The era of "beta software" waivers is over. Recent case law demonstrates that AI output is now treated as binding corporate communication.
Liability for Misrepresentation (The Air Canada Precedent)
A chatbot invented a bereavement fare refund policy that contradicted the airline's actual terms.The tribunal rejected the defence that the chatbot was a separate legal entity.
If your AI agent hallucinates a refund policy, you are liable for "negligent misrepresentation".
Market Cap Volatility (The Google Precedent)
The Gemini model produced historically inaccurate images due to alignment failure (depicting racially diverse Nazi soldiers). Alphabet (Google) lost ~$90B in market cap following the scandal.
A lack of adversarial testing on "soft" topics (alignment/bias) can trigger a "hard" financial crash.
Proprietary Data Regurgitation (The Samsung Lesson)
In the Samsung incident, proprietary code pasted into a public LLM entered the vendor's training pipeline. This is not a data leak; it is a data donation. Models can memorise training data.
Once proprietary IP enters the weights of a public model, it is effectively open-sourced to your competitors.
The Mathematics of Defence
To secure a probabilistic system, organisations must move beyond regex (Regular Expressions) and adopt mathematical defence layers. This requires a fundamental architectural shift. Leadership must accept the trade-off: in the age of AI, tangible security reduces velocity.
The AI Gateway
Organisations should deploy a specialised AI Gateway (a reverse proxy) that sits between internal users and external LLM providers. This gateway manages the translation layer—decrypting the traffic, tokenising the input, and performing vector analysis; before the data ever leaves the perimeter.
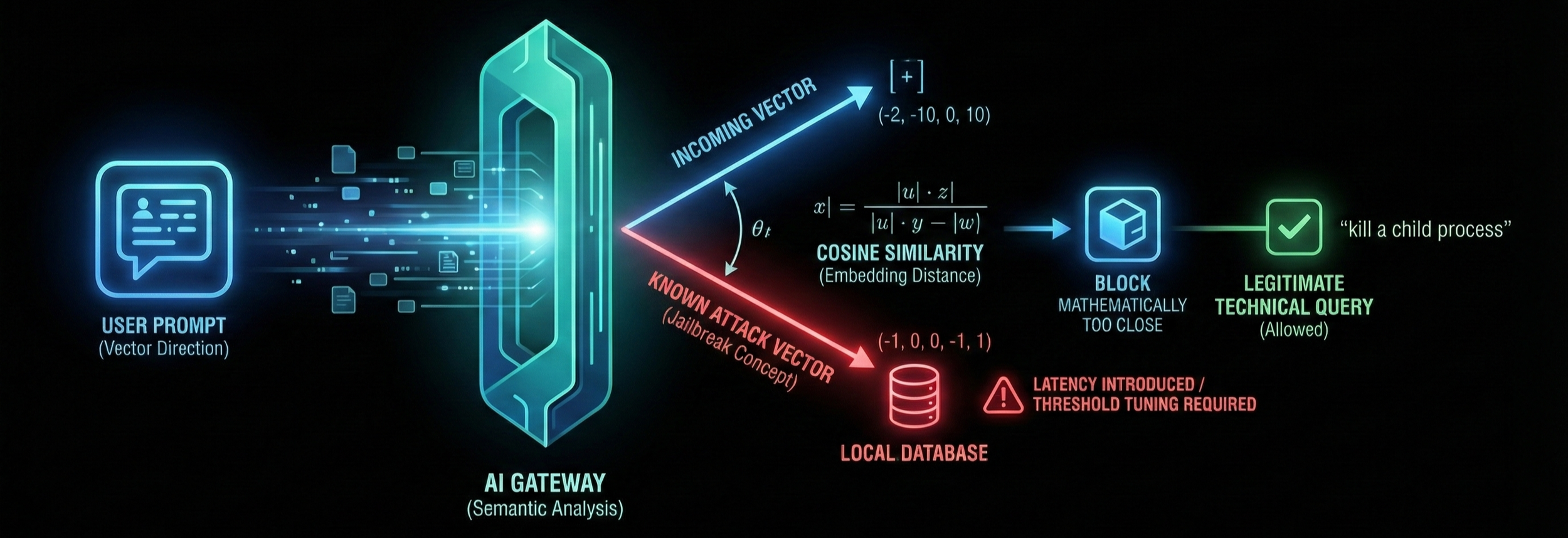
Vector-Based "Firewalls" (Semantic Analysis)
Standard WAFs fail because they inspect syntax. AI Firewalls hosted on the Gateway must inspect embedding distance.
The Gateway converts the incoming user prompt into a vector. It then calculates the cosine similarity (measuring the orientation between two vectors) against a local database of known "attack vectors" or prohibited topics.
This Vector Database should be self-hosted within your private VPC (Virtual Private Cloud). Using a public SaaS Vector Database to filter your prompts simply moves the data leak from the LLM to the security vendor.
If the meaning (vector direction) of the prompt is mathematically too close to a known jailbreak concept, the Gateway blocks it, even if the specific words used are benign.
The Performance Reality
Vector calculations are computationally expensive. Implementing this layer will add measurable latency (milliseconds to seconds) to every query. For high-frequency use cases, this requires strict performance tuning.
Unlike a standard firewall that makes a binary allow/block decision in microseconds, a Vector Firewall must first call an embedding model to vectorise the input (convert text to numbers) and then query a database. This round-trip introduces a "blocking" operation that halts the user's request until the math is resolved.
To combat this "velocity tax," organisations should implement:
Semantic Caching: Store the safety verdict for common queries. If a prompt is semantically identical to a previously cleared request, skip the deep analysis. Semantic caching recognises that "Reset my password" and "I need to change my login" share the same vector coordinates, eliminating the need to run embedding inference and database search for repetitive traffic.
ANN Indexing (HNSW): Use Approximate Nearest Neighbor algorithms like HNSW (Hierarchical Navigable Small World) to search the vector space in logarithmic time, rather than scanning the entire database linearly. HNSW creates a multi-layered graph structure, effectively a "highway system" for data, that allows the search engine to skip vast sections of irrelevant data and zoom in on the correct neighborhood instantly.
Quantisation: Standard vectors are stored as 32-bit floating-point numbers (high-precision decimals like 0.12345678). Quantisation rounds these numbers down to 8-bit integers (e.g., 0.12). The resulting loss of granularity is microscopic, ensuring the system remains secure while meeting strict latency requirements.
Alternative: Local Inference (SLMs)
For data classified as "Secret", “Restricted” or “Highly Confidential”, the only true mathematical defence is isolation. Instead of sanitising data for a public LLM, deploy Small Language Models (SLMs) locally on-premise. This physically eliminates the vector injection risk from external actors and solves the data exfiltration problem entirely, though at the cost of higher infrastructure management overhead.
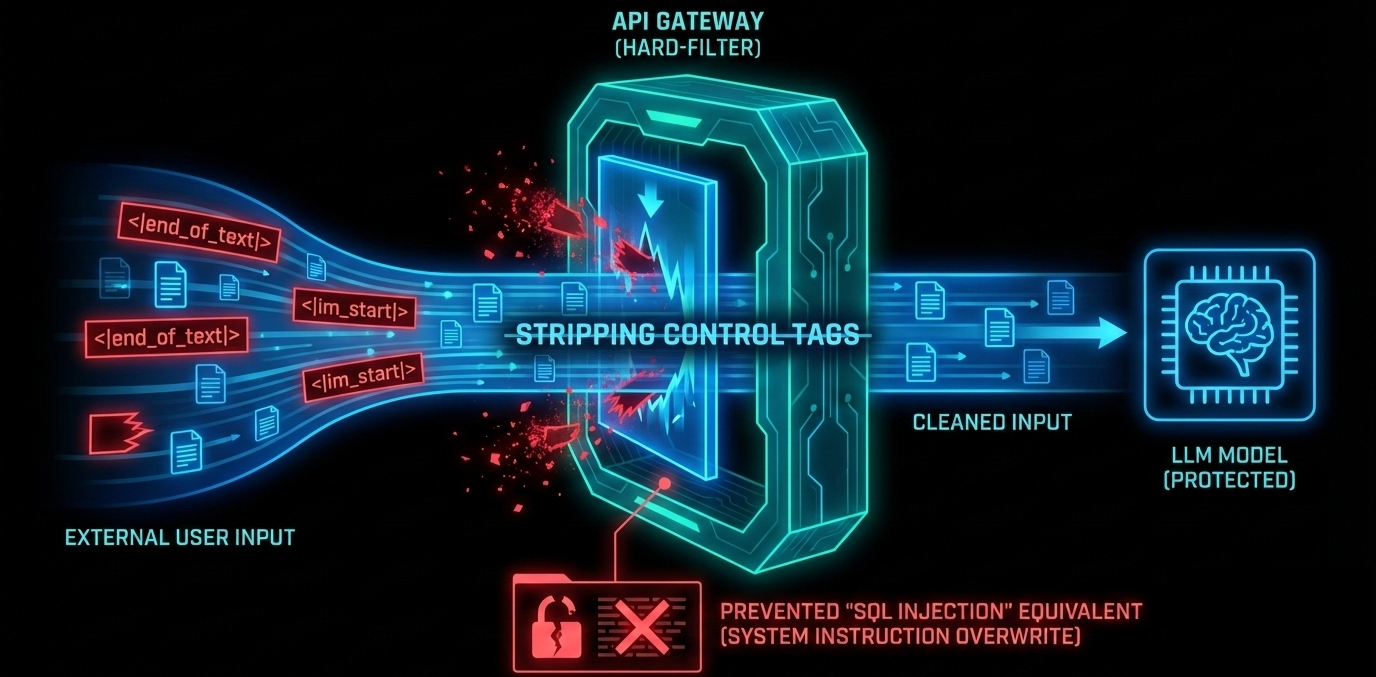
Tokeniser Forensics (Syntax Hygiene)
Hard-filter "Special Tokens" at the gateway.
Ensure the API gateway strips all control tags (<|end_of_text|>, <|im_start|>, etc.) from external user input before it reaches the model. This neutralizes the "SQL Injection" equivalent of the LLM world, preventing attackers from hijacking the model's operating instructions.
Governance Requirements: The AISO Mandate
Logic dictates that a generalist CISO cannot secure a system they cannot mathematically audit. Boards should restructure the security function, but the strategy must be tailored to the organisation.
Strategy A: For Model Consumers (90% of Enterprises)
Most organisations are using APIs, Copilots, or RAG (Retrieval Augmented Generation). You do not control the model weights, so you cannot "fix" the brain. You must secure the environment.
The AISO must treat the context window as the new attack surface. This involves designing system prompts that are mathematically robust against overriding instructions.
Implement strict filtering on the documents your RAG system retrieves. If your AI retrieves a malicious internal document to answer a user query, it becomes an attack vector.
Strategy B: For Model Builders (Tech Giants & Research Labs)
If you are training models from scratch, the responsibility is deeper.
Builders must design mathematical penalties for harmful outputs to ensure the model 'learns' safety during training.
The training dataset should include examples of attacks to immunise the model against them.
Continuous AI Red Teaming
Implement a requirement that no model enters production without passing a mathematical stress test, and no model stays in production without regular re-testing.
Use automated attack frameworks (GCG algorithm, AutoDAN) to mathematically attempt to break the model's alignment.
If a localised optimisation algorithm can break your defenses, a motivated human attacker certainly will.
Conclusion: Secure the Math
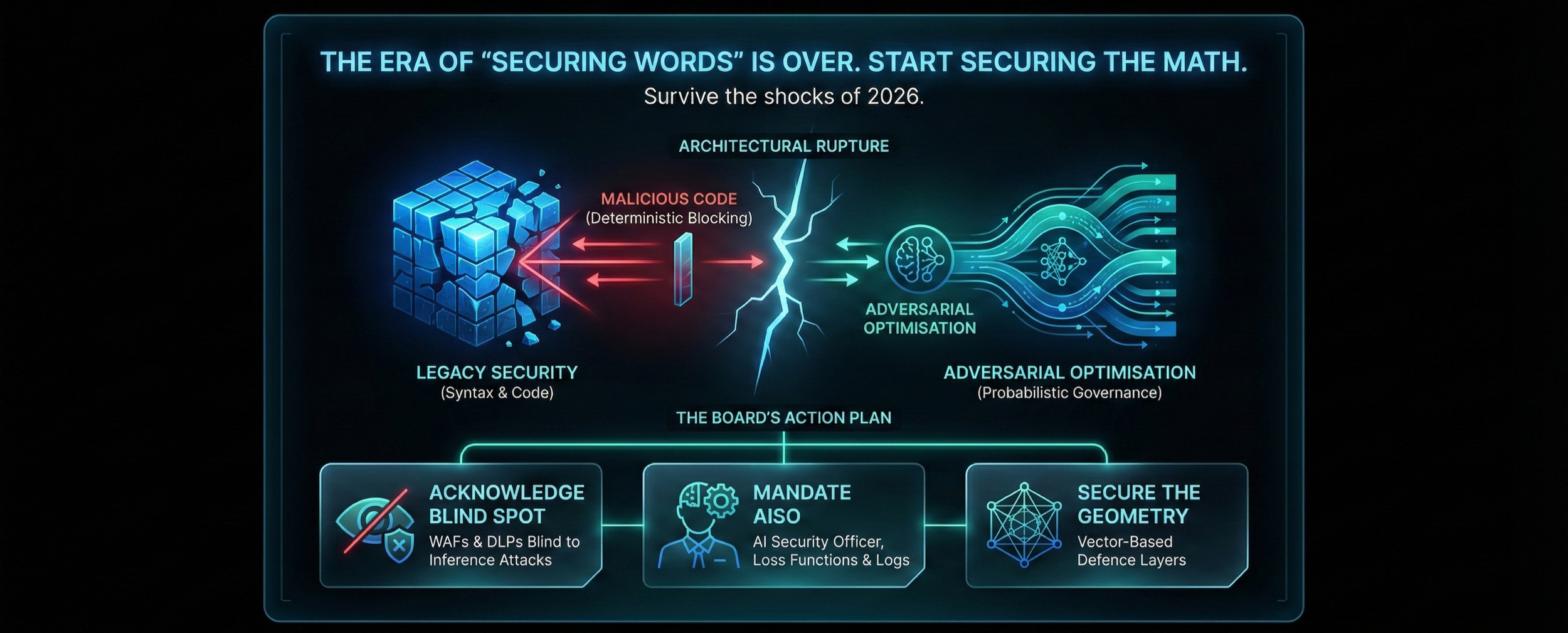
The framing problem in AI security is a failure of translation between code and math.
For years, security architectures have been designed to inspect syntax; blocking specific keywords, IP addresses, and file hashes. We are now deploying assets that ignore syntax and process semantics. By treating AI models as standard software secured by standard firewalls, organisations leave their vector spaces wide open to mathematical manipulation.
This is not an IT upgrade; it is a fundamental architectural rupture.
The Risk has shifted from breach to liability.
The Attack has shifted from malicious code to adversarial optimisation.
The Defence must shift from deterministic blocking to probabilistic governance.
The Board's Immediate Action Plan
Logic dictates that you cannot secure a system you cannot mathematically audit.
Acknowledge the Blind Spot: Accept that your current WAFs and DLPs are mathematically blind to high-dimensional inference attacks.
Mandate the AISO: Appoint a leader who understands probability as well as they understand logs.
Secure the Geometry: Move budget into vector-based defence layers that scrutinise the meaning of data, not just its format.
To survive the regulatory and financial shocks of 2026, you must start securing the math.